It's almost the end of 2019, and I've been thinking back over the year as well as thinking ahead to 2020. In past years, I've often evaluated my "nights and weekends" projects using the same metrics I'm evaluated on at work: projects completed, and results obtained. This year, I've started looking my my "nights and weekends" efforts through a different lens focused more on the knowledge I've gained than just what I've produced.
As an aside, given the cover image, I do find it somewhat ironic that almost none of the knowledge I gained this year came from printed and bound books. Growing up with a love of libraries, and the fascinating collections of books they contained, it's both sad to think that knowledge is no longer concentrated there, and amazing to realize what a wealth of knowledge is now so easily-accessible just a short search away.
Looking back, there are two themes that run through several areas that I worked in across the year. The first of these is making software more modular, collaborative, and accessible. The second is Python. That's not all, though. So, let's get right to it!
Software Packaging and Distribution
Professionally, I come from a standard commercial-software background, and have often looked at open source through a similar lens. Specifically, I've often focused on software that can be packaged such that it's easily accessible to end users. This means bundling dependencies, providing installers, etc (see DVKit, a 'batteries-included' IDE for verification engineers).
This application-centric approach works well so long as the elements of functionality being distributed are relatively small in number, and the ways in which they need to be combined are fairly limited. This approach breaks down when the elements of functionality are relatively large in number, and need to be combined in many ways. In short, the more modular software becomes, the less feasible typical application-centric packaging becomes.
I've been dabbling for a few years in RTL design and verification. In this space, the verification environment for a given design will depend on many small elements of functionality -- utility libraries, reusable verification IP, etc. Bundling the dependencies with the verification environment quickly leads to projects that require lots of disk space. On the other hand, forcing users to download and install all the dependencies presents a significant barrier to new users.
One of the biggest reasons that I've spent so much time with Python this past year is that the Python ecosystem appears to provide a solution to this challenge of packaging and easily distributing small elements of functionality. Over the course of the year, I've spent time looking at Conda as a way of making application-level features more modular and easily-accessible. I've also spent time learning about how to package Python extension libraries (both with and without native library components) for distribution on PyPi, a repository for distributing Python packages.
New Approaches to Embedded DSLs
I've been involved in several projects over the years that have used C++ to provide a language-like user experience via C++ overloaded operators and macros. While there are certainly downsides to these embedded domain-specific languages in terms of error messaging and extensibility, an embedded domain-specific language can be a great way to prototype a language-based user interface before committing to the work of defining a first-class language and creating the parsing and processing infrastructure. It's also a very helpful approach for exploring new techniques in the context of existing languages.
C++ support for macros and operator overloading have been used for embedded DSLs from the beginning. However, using just these features tends to lead to somewhat awkward syntax, since operator overloading only supports expressions. C++11 (and beyond) brings new features, such as lambda expressions, and I spent time investigating these mechanisms and their impact on supporting expressing more-complex constructs in a more-natural way.
While the new C++11 features definitely showed promise, I started to wonder what support Python provided for implementing embedded domain-specific languages. As it turns out, Python provides some very powerful capabilities. Python supports overloading more operators than C++, and supports introspection into the code described by the user. I definitely intend to revisit embedded domain-specific languages captured in Python in 2020!
Constraint Solvers
Highly-capable constraint solvers that are available under permissive open-source licenses are becoming widely available, and I'm seeing these solvers applied to a range of interesting tasks. The CRAVE library for generating random stimulus has been around for some time. Several tools are leveraging available SMT solvers for model checking. Constraint solvers are even being applied for graphical layout of diagrams!
Given the range of applications to which solvers lend themselves, I thought it would be worth having a bit more hands-on knowledge. I spent some time learning about the Z3 solver API before concluding that, while the API is elegant and comprehensive, it's also more-complicated that what I need. I subsequently shifted to looking at the Boolector solver API, which is smaller and simpler.
The Boolector solver provides a Python binding, which is built along with the solver. This means that a user needs to manually build Boolector in order to use a Python package that uses the Boolector solver. Fortunately, I'd been learning about packaging and distributing Python extension libraries, and this this provided a perfect place to try this out. The Boolector Python library (PyBoolector) on PyPi is the result of this work.
Python for Verification
My background in verification is rooted in SystemC, SystemVerilog, and UVM. All very mainstream languages and methodologies in the commercial design and functional verification space. As I spent more time exploring Python and the modular and collaborative packaging it supports, I concluded that it made sense to investigate using Python for functional verification.
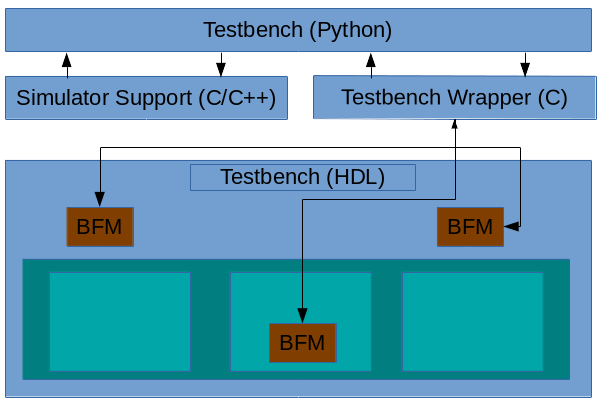
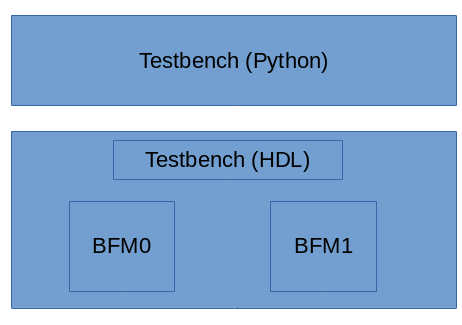
I spent time learning about cocotb, the most popular functional verification library in Python that I'm aware of. I also spent time learning about Python's back-end C API and how to structure bus-functional models to integrate at the procedure level with Python.
Actually, the more time I spend looking at Python for verification, the more possibilities I see. Definitely look for more on this topic in 2020!
In most areas, I've been quite happy with Python for verification. The object-oriented language features fit the requirements for high-level verification, and the easy availability of utility packages simplifies dealing with project dependencies. The one thing I've been dissatisfied with is support for static checking. I've used statically-typed languages for most application development. These languages have the advantage that the compiler can identify misuse of types before running the application. Dynamically-typed languages, such as Python and TCL, end up discovering type-misuse issues (eg passing an object to a method that expects an object of a different type) at runtime. One target for 2020 is learning more about what can be done to address this issue. Lint tools such as Pylint help, and my hope is to discover more tools and methodologies that help to close this gap.
RTL Design Skills
When I undertook the 2018 RISC-V Soft Core Contest, It had been quite a few years since I'd done any RTL design. Going through the design work for that project helped me brush up my skills quite a bit, but I knew I had quite a ways to go to be proficient. When the 2019 contest, centered around software security, came along, I knew it was a good opportunity to both learn more about software security vulnerabilities and improve my RTL design skills.
In addition to improving my RTL design skills, I learned a couple of things from initially attempting to add a few new features (multiplication, compressed instructions, security extensions) to my 2018 soft core. First, I had succeeded at writing some very good spaghetti RTL that wasn't modular enough to support extensibility. Furthermore, I didn't have sufficient tests to effectively and efficiently catch bugs introduced by adding new features.
Over the course of the 2019 project, I did a complete rewrite of the Featherweight RISC core. The more-modular structure of the rewritten core lends itself even better to bounded model checking, and I found this to be extremely helpful in catching and diagnosing bugs introduced during development and integration.
Going through this process also helped to improve my knowledge of RTL constructs that result in good efficient implementation, and which do not.
Looking Forward
2019 has been a great year for learning about more corners of the technical world. Looking forward to 2020, I see more work with Python, transitioning more of my existing projects over to cloud-based continuous integration, and more work with Python in the functional verification space. What will I learn along the way? Stay tuned for more blog posts across 2020 to find out!
As we come to the end of 2019 and the beginning of a new year (and new decade), I wish you happy holidays, a happy new year, and a 2020 ahead that is full of learning!
Disclaimer
The views and opinions expressed above are solely those of the author and do not represent those of my employer or any other party.