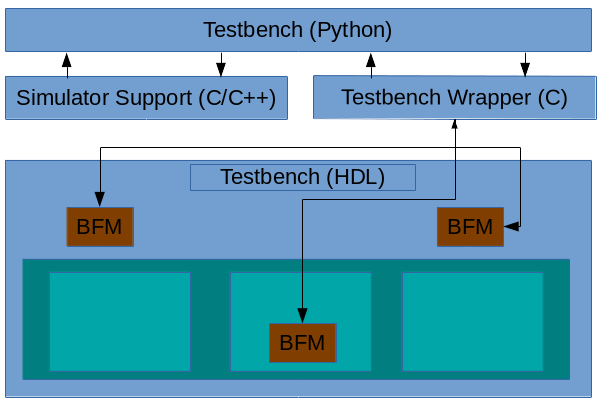
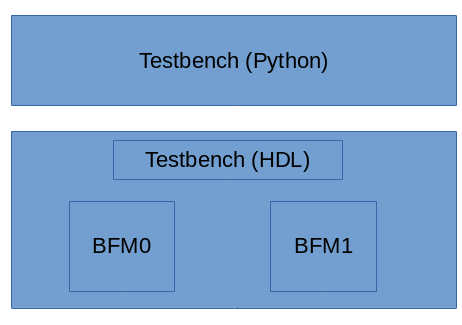
Intro
In my last post, I talked about a prototype procedural interface between Python and HDL that enables cross-calling between Python and SystemVerilog. My primary motivation for investigating a procedural interface was its potential to maximize performance. In this post, I create a Python testbench for a small IP and compare it to the equivalent C++ testbench. I also look at the performance of Python for verification.
Creating a Python Testbench
My go-to IP for trying out new verification techniques is a small 32-bit RISC-V core named Featherweight RISC (FWRISC) that I created for a design contest last year. The original testbench was written in C++, so that will be my baseline for comparison. If you're interested in the structure of the testbench, have a look at this post.
Since I was keeping the testbench structure the same, I didn't expect much in terms of a reduction in lines of code. C++ is a bit verbose, in that it expects a header and implementation file for each class. This contributes to the fact that each C++ test is roughly twice as long as each Python test:
Since I was keeping the testbench structure the same, I didn't expect much in terms of a reduction in lines of code. C++ is a bit verbose, in that it expects a header and implementation file for each class. This contributes to the fact that each C++ test is roughly twice as long as each Python test:
- C++ Test: 328 lines
- Python Test: 139 lines
Reducing the lines of code is a good thing, since more code statistically means more bugs, and spending time finding and fixing testbench bugs doesn't help us get our design verified. But, that's just the start.
The unit tests for FWRISC are all self-checking. This means that each assembly file contains the expected value for registers modified by the test. You can see the data embedded below between the start_expected and end_expected labels.
| entry: | |
| li x1, 5 | |
| add x3, x1, 6 | |
| j done | |
| // Expected value for registers | |
| start_expected: | |
| .word 1, 5 | |
| .word 3, 11 | |
| end_expected: |
Because I didn't want to need to install an ELF-reading library on every machine where I wanted to run the FWRISC regression, I wrote my own small ELF-reading classes for the FWRISC testbench. This amounted to ~400 lines of code, and required a certain amount of thought and effort.
When I started writing the Python testbench, I thought about writing another ELF-reader in Python based on the code I'd written in C++... But then I realized that there was already a Python library for doing this called pyelftools. All I needed to do was get it installed in my environment (more on that in a future post), and call the API:
| with open(sw_image, "rb") as f: | |
| elffile = ELFFile(f) | |
| symtab = elffile.get_section_by_name('.symtab') | |
| start_expected = symtab.get_symbol_by_name("start_expected")[0]["st_value"] | |
| end_expected = symtab.get_symbol_by_name("end_expected")[0]["st_value"] | |
| section = None | |
| for i in range(elffile.num_sections()): | |
| shdr = elffile._get_section_header(i) | |
| if (start_expected >= shdr['sh_addr']) and (end_expected <= (shdr['sh_addr'] + shdr['sh_size'])): | |
| start_expected -= shdr['sh_addr'] | |
| end_expected -= shdr['sh_addr'] | |
| section = elffile.get_section(i) | |
| break | |
| data = section.data() |
That's a pretty significant savings both in terms of code, and in terms of development and debug effort! So, definitely my Python testbench is looking pretty good in terms of productivity. But, what about performance?
Evaluating Performance
Testbench performance may not be the most important factor when evaluating a language for use in verification. In general, the time an engineer takes to develop, debug, and maintain a verification environment is far more expensive than the compute time taken to execute tests. That said, understanding that performance characteristics of any language enables us to make smarter tradeoffs in how we use the language.

I was fortunate enough to see David Patterson deliver his keynote A New Golden Age for Computer Architecture around a year ago at DAC 2018. The slide above comes from that presentation, and compares the performance of a variety of implementations of the computationally-intensive matrix multiply operation. As you can see from the slide, a C implementation is 50x faster than a Python implementation. Based on this slide and the anecdotal evidence of others, my pre-existing expectations were somewhat low when it came to Python performance. But, of course, having concrete data specific to functional verification is far more useful than a few anecdotes and rumors.
Spoiler alert: C++ is definitively faster than Python.
As with most languages, there are two aspects of performance to consider with Python: startup time and steady-state performance. Most of the FWRISC tests are quite short -- in fact, the suite of unit tests contains tests that execute less than 10 instructions.This gives us a good way to evaluate the startup overhead of Python. In order to evaluate the steady-state performance, I created a program that ran a tight loop with 10,000,000 instructions. The performance numbers below all come from Verilator-based simulations.
Startup Overhead
As I noted above, I evaluated the startup overhead of Python using the unit test suite. This suite contains 66 very short tests.
Startup Overhead
As I noted above, I evaluated the startup overhead of Python using the unit test suite. This suite contains 66 very short tests.
- C++ Testbench: 7s
- Python Testbench: 18s
Based on the numbers above, Python does impose a noticeable overhead on the test suite -- it takes ~2.5x longer to run the suite with Python vs C++. That said, 18 seconds is still very reasonable to run a suite of smoke tests.
Steady-State Overhead
To evaluate the steady-state overhead of a Python testbench, I ran a long-loop test that ran a total of 10,000,000 instructions.
Steady-State Overhead
To evaluate the steady-state overhead of a Python testbench, I ran a long-loop test that ran a total of 10,000,000 instructions.
- C++ Testbench: 11.6s
- Python Testbench: 109.7s
Okay, this doesn't look so good. Our C++ testbench is 9.45x faster than our Python testbench. What do we do about this?
Adapting to Python's Performance
Initially, the FWRISC testbench didn't worry much about interaction between the design and testbench. The fwrisc_tracer BFM called the testbench on each executed instruction, register write, and memory access. This was, of course, simple. But, was it really necessary?
Actually, in most cases, the testbench only needs to be aware of the results of a simulation, or key events across the simulation. Given the cost of calling Python, I made a few optimizations to the frequency of events sent to the testbench:
Actually, in most cases, the testbench only needs to be aware of the results of a simulation, or key events across the simulation. Given the cost of calling Python, I made a few optimizations to the frequency of events sent to the testbench:
- Maintain the register state in the tracer BFM, instead of calling the testbench every time a write occurs. The testbench can read back the register state at the end of the test as needed.
- Notify the testbench when a long-jump or jump-link instruction occurs, instead of on every instruction. This allows the testbench to detect end-of-test conditions and minimizes the frequency of calls
With these two enhancements to both the C++ and Python testbenches, I re-ran the long-loop test and got new results:
- C++ Testbench: 4s
- Python Testbench: 5s
Notice that the C++ results have improved as well. My interpretation of these results is that most of the time is now spent by Verilator in simulating the design, and the results are more-or-less identical.
Conclusions
The Python ecosystem brings definite benefits when applying Python for functional verification. The existing ecosystem of available libraries, and the infrastructure to easily access them, simplifies the effort needed to reuse existing code. It also minimizes the burden placed on users that want to try out an open source project that uses Python for verification.
Using Python does come with performance overhead. This means that it's more important to consider how the execution of the testbench relates to execution of the design. A testbench that interacts with the design frequently (eg every clock) will impose much greater overhead compared to a testbench that interacts with the design every 100 or 1000 cycles. There are typically many optimization opportunities that minimize the performance overhead of a Python testbench, while not adversely impacting verification results.
It's important to remember that engineer time is much more expensive than compute time, so making engineers more productive wins every time. So, from my perspective, the real question isn't whether C++ is faster than Python. The real questions are whether Python is sufficiently fast to be useful, and whether there are reasonable approaches to dealing with the performance bottlenecks. Based on my experience, the answer is a resounding Yes.
It's important to remember that engineer time is much more expensive than compute time, so making engineers more productive wins every time. So, from my perspective, the real question isn't whether C++ is faster than Python. The real questions are whether Python is sufficiently fast to be useful, and whether there are reasonable approaches to dealing with the performance bottlenecks. Based on my experience, the answer is a resounding Yes.
Disclaimer
The views and opinions expressed above are solely those of the author and do not represent those of my employer or any other party.