Getting a project started -- even to a certain level of completeness -- is often pretty simple. A couple weekends of hacking often results in pretty good progress and results. Finishing things up, in contrast, is often a slow process. That has certainly been the case with some work I did back in May and June this year to prototype a task-based interface between Python and an HDL simulator. The proof-of-concept work I did at the time seemed quite promising, but the clear next step was to make that work more accessible to others. That "last little bit of work" has certainly turned out to take more time that I had originally assumed!
Just as a reminder, the motivation for interacting with an HDL environment at the task level is quite simple: performance. Communicating across language (especially interpreted language) boundaries tends to be expensive, so minimizing the number of cross-language communications is critical to achieving high throughput. Using a task-based interface between Python and an HDL environment boosts performance in three ways. First, a task-based interface groups data so fewer language-boundary crossings are required to communicate a given amount of data. Secondly, and more importantly, using a task-based interface enables the HDL environment to filter events and only interact with the Python environment when absolutely necessary. Finally, using a task-based interface enables integrations with high(er)-speed environments, such as emulation or the current release of Verilator, where signal-level integration isn't practical.
I started looking at Python as a testbench language for reasons that might initially seem strange: the Python ecosystem (primarily PyPi) that makes it easy to publish bits of library and utility code in a way that it is easily-accessible to others. Often, the ability to take advantage of the work of others is gated by the effort required to gather all the required software dependencies. The Python ecosystem promises to alleviate that challenge, and I was excited to explore the possibilities.
Where Does it Fit?
I'm aware of a few projects that use Python for verification, but it currently appears that Cocotb is the most visible Python-based testbench for doing hardware verification using Python testbench code. Consequently, it made very good sense to see whether the task-based integration I had prototyped could be integrated with the existing Cocotb library.
Cocotb is a Python library that supports light-weight concurrency via co-routines, and provides primitives for coordinating these co-routines with each other and with activity in a HDL simulation environment. In addition to the Python library, Cocotb provides native-compiled C/C++ libraries that integrate with the simulation environment via APIS implemented by the simulator (VPI, DPI, FLI, or VHPI depending on the simulator). Currently, Cocotb interacts with simulation environments at the signal level.
In considering how to add task-based interactions to Cocotb, there were a several requirements that I thought were quite important. First, the user should not be forced to choose between signal-level and task-based interactions between Python and HDL. It should be possible to introduce task-based interactions to a testbench currently interacting at the signal level, or add a few signal-based interactions to a testbench that primarily interacts at the task level. Secondly, a task-based integration must support a range of simulator APIs. I had prototyped a DPI-based integration, which is supported by SystemVerilog simulators, supporting Verilog and VHDL simulators as well was clearly important. Finally, achieving good performance was a key requirement, since performance is the primary motivation for using a task-based interface in the first place.
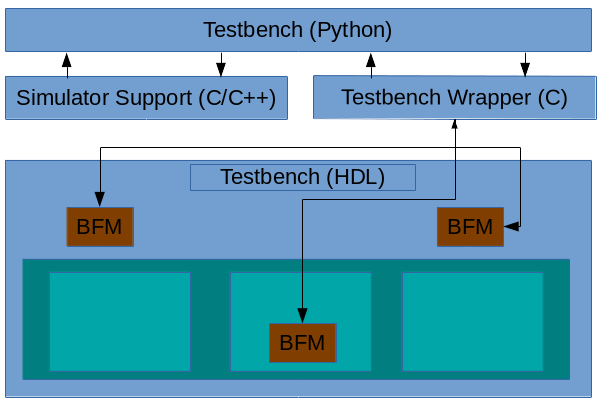
Task-Based BFM Cocotb Architecture
 From a system perspective, the diagram above captures how task-based BFMs integrate with Cocotb. Each BFM instance is represented in the HDL environment by an instance of an HDL module. This module is special, in that it knows how to accept and make task calls and convert between signal-level information and those task calls.
From a system perspective, the diagram above captures how task-based BFMs integrate with Cocotb. Each BFM instance is represented in the HDL environment by an instance of an HDL module. This module is special, in that it knows how to accept and make task calls and convert between signal-level information and those task calls.
Each BFM also knows how to register itself with a BFM Manager within Cocotb. When the HDL portion of a BFM registers with Cocotb, the BFM Manager creates an instance of a Python class that represents the BFM within the Python environment.
The BFM Manager provides methods to allow the user's test code to query the available BFMs and obtain a handle to the BFM instances required by the test. From there, the user's test simply calls methods on the Python class object and/or receives callbacks.

Each BFM also knows how to register itself with a BFM Manager within Cocotb. When the HDL portion of a BFM registers with Cocotb, the BFM Manager creates an instance of a Python class that represents the BFM within the Python environment.
The BFM Manager provides methods to allow the user's test code to query the available BFMs and obtain a handle to the BFM instances required by the test. From there, the user's test simply calls methods on the Python class object and/or receives callbacks.
Task-Based BFM Architecture
Let's take a quick look at the work needed to support a task-based BFM. First off, the BFM author needs to a Python class to implement the Python side of the BFM. That class is decorated with a @cocotb.bfm decorator that associates HDL template files with the BFM class. Below is a BFM for a simple ready/valid protocol.
@cocotb.bfm(hdl={
cocotb.bfm_vlog : cocotb.bfm_hdl_path(__file__, "hdl/rv_data_out_bfm.v"),
cocotb.bfm_sv : cocotb.bfm_hdl_path(__file__, "hdl/rv_data_out_bfm.v")
})
class ReadyValidDataOutBFM():
# ...
Next, the BFM author must specify the low-level interaction API with the HDL BFM. All calls must be non-blocking, so most interactions with the HDL environment are implemented as a request/acknowledge pair of API calls.
@cocotb.bfm_import(cocotb.bfm_uint32_t)
def write_req(self, d):
pass
@cocotb.bfm_export()
def write_ack(self):
self.ack_ev.set()
Calling a class methods decorated with @cocotb.bfm_import will result in a task call in the HDL BFM. Class methods decorated with @cocotb.bfm_export can be called from the HDL BFM.
Finally, on the Python side, the BFM author will likely provide a convenience API to simplify the testwriter's life:
@cocotb.coroutine
def write_c(self, data):
'''
Writes the specified data word to the interface
'''
yield self.busy.acquire()
self.write_req(data)
# Wait for acknowledge of the transfer
yield self.ack_ev.wait()
self.ack_ev.clear()
self.busy.release()
There's one piece left, and that's the HDL BFM. This is specified as a template:
module rv_data_out_bfm #(
parameter DATA_WIDTH = 8
) (
input clock,
input reset,
output reg[DATA_WIDTH-1:0] data,
output reg data_valid,
input data_ready
);
reg[DATA_WIDTH-1:0] data_v = 0;
reg data_valid_v = 0;
always @(posedge clock) begin
if (reset) begin
data_valid <= 0;
data <= 0;
end else begin
if (data_valid_v) begin
data_valid <= 1;
data <= data_v;
data_valid_v = 0;
end
if (data_valid && data_ready) begin
write_ack();
if (!data_valid_v) begin
data_valid <= 0;
end
end
end
end
task write_req(reg[63:0] d);
begin
data_v = d;
data_valid_v = 1;
end
endtask
// Auto-generated code to implement the BFM API
${cocotb_bfm_api_impl}
endmodule
The BFM author must implement tasks that will be called from the Python class. Task proxies that will invoke Python methods are implemented by the Cocotb automation, and substituted into the template where the ${cocotb_bfm_api_impl} tag is specified.
Current Integrations
Currently, task-based BFM integrations are implemented for Verilog via the VPI interface and for SystemVerilog via the DPI interface. A VHDL integration isn't currently supported, but that's on the roadmap. One complication with VHDL is that there are actually several interfaces that may need to be supported depending on the simulator -- VHPI, VHPI via VPI, Modelsim FLI. Here I could use some input from the community on priorities, so I'd definitely like to hear from you if you're using Cocotb with VHDL...
Results
As I mentioned at the beginning of this post, performance is the primary reason for using task-based interaction between Python and a HDL environment. So, how much improvement can you expect? Well, that entirely depends on how frequently your tests interact with the HDL environment and, to a certain extent, on how long your tests are. If your testbench needs to interact with the testbench every clock cycle, then you're unlikely to see much benefit. If, however, your testbench spends quite a few cycles waiting for the design to respond, then you're likely to see pretty significant benefits.
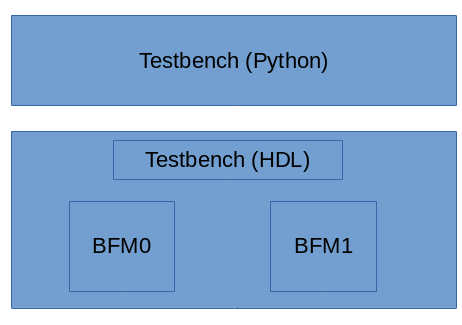
I'll use my FWRISC (Featherweight RISC) RISCV core as an example. In this environment, the bulk of the test is actually compiled code that executes on the processor. The Python testbench is primarily responsible for checking results and providing debug information when needed.

A diagram of the simulation-based testbench is shown above. The Tracer BFM is responsible for monitoring execution of the FWRISC core and sending events up to the high-level testbench as needed. These events include:
- Instruction executed
- Register written
- Memory written
I've created two Cocotb implementations of this BFM: one that interacts at the signal level, and one that interacts at the task level. To compare the performance, I'm running a Zephyr test with Icarus Verilog for 10ms of simulation time.
Let's start with as close to a direct comparison as possible. Both the signal-level and task-based BFM will capture the same information and propagate it to the Python testbench.
- Signal-Level BFM: 85s (wallclock)
- Task-Level BFM: 33s (wallclock)
Okay, so already we're looking pretty good. This performance increase is simply because the task-based BFM doesn't need to call the Python environment every cycle.
Another way we can benefit is to use a higher-performance simulator. Icarus Verilog is interpreted, and supports a full event-driven simulation environment. Verilator has a much more restricted set of features (synthesizable Verilog only, limited signal-level access, etc), but is also much faster. It also doesn't currently support the signal-level access to the extent necessary to do a direct comparison between a task-based BFM and a signal-level BFM. So, how do we look here? I actually had to increase the simulation time to 100ms (10x longer) to get a meaningful reading.
- Task-Level BFM: 18s (wallclock)
So, coupling a fast execution platform with an efficient integration mechanism definitely brings benefits!
Next Steps
So, where do we go from here? Well, please stay tuned for my next blog post to get more details on how create task-based BFMs using these features. I also have an active pull request (#1217) to get this support merged into Cocotb directly. Until then, you can always access the code here.
Disclaimer
The views and opinions expressed above are solely those of the author and do not represent those of my employer or any other party.